Getting Started
Installation
EffiARA is available as a PyPI package.
pip install effiara
You can also install from source like so
git clone https://github.com/MiniEggz/EffiARA.git
cd EffiARA
pip install -r requirements.txt
python setup.py develop
Fundamentals
Data Format
EffiARA assumes a common data format for all annotations. This format is a pandas.DataFrame
object with a column for each annotation from each annotator. The column name format for a user’s annotations is
{username}_label and each row is a unique sample.
Let’s assume we have the following CSV file saved as “example.csv”.
Larry_label |
Curly_label |
Moe_label |
|---|---|---|
yes |
no |
yes |
no |
no |
|
yes |
yes |
|
no |
no |
no |
We thus have three annotators –Larry, Curly, and Moe– and four examples. Our task is binary with “yes” or “no” labels. We also see that some annotators have not annotated some samples. This is fine. EffiARA will account for this when computing agreement. Let’s read this data into Python.
import pandas as pd
annotations = pd.read_csv("example.csv")
print(annotations)
Larry_label Curly_label Moe_label
0 yes no yes
1 no no NaN
2 NaN yes yes
3 no no no
Computing Agreement
Computing agreement between our annotators is done using the Annotations class. We simply instantiate this class with our annotations DataFrame and get agreements and annotator reliabilities like so.
from effiara.annotator_reliability import Annotations
# overlap_threshold is the minimum number of samples
# annotated by a pair of annotators to compute inter-annotator
# agreement. It's default is 15, so we need to set it lower
# because we only have 4 examples.
annos = Annotations(annotations, overlap_threshold=1)
print(annos)
Node Larry has the following attributes:
reliability: 1.040292317713493
intra_agreement: 1
avg_inter_agreement: 0.5874928354635361
Node Curly has the following attributes:
reliability: 0.8083601730435107
intra_agreement: 1
avg_inter_agreement: 0.2335628758666486
Node Moe has the following attributes:
reliability: 1.151347509242996
intra_agreement: 1
avg_inter_agreement: 0.7569637792475039
Different agreement metrics can be specified via the agreement_metric argument to the
Annotations class. The available metrics are:
Krippendorff’s alpha (
"krippendorff")Cohen’s kappa (
"cohen")Fleiss’ kappa (
"fliess")Multi-label Krippendorff’s alpha (
"multi_krippendorff")Cosine similarity (
"cosine")
The first three metrics assume hard labels. Multi-label Krippendorff, as the name suggests, is designed for tasks where each sample can have multiple labels assigned to it. Cosine similarity assumes soft, probabilistic labels (see Creating a LabelGenerator for guidance on using soft labels in EffiARA).
Minimum Working Example
Below is a full working example of how to use EffiARA. We employ some helper functions to generate data
points and annotations, then read these into the Annotations class to compute agreement.
from effiara.annotator_reliability import Annotations
from effiara.data_generator import (
annotate_samples,
concat_annotations,
generate_samples,
)
from effiara.label_generators import DefaultLabelGenerator # noqa
from effiara.preparation import SampleDistributor
# Generate some random data to annotate.
num_classes = 3
num_samples = 500
df = generate_samples(num_samples, num_classes, seed=0)
# Name and percentage correctness for each annotator.
annotators = ["Larry", "Curly", "Moe"]
correctness = [0.95, 0.67, 0.58]
annotator_dict = dict(zip(annotators, correctness))
print(annotator_dict)
# Initialize the sample distributor.
# Note that one of the __init__ variables must be None.
sample_distributor = SampleDistributor(
annotators=annotators,
time_available=10,
# This is unknown. SampleDistributor will solve for it.
annotation_rate=None,
num_samples=num_samples,
double_proportion=1 / 3,
re_proportion=1 / 2,
)
sample_distributor.set_project_distribution()
print(sample_distributor)
# Distribute the samples to the annotators.
allocations = sample_distributor.distribute_samples(df.copy())
# Generate annotations according to allocations and annotator correctness.
annotated = annotate_samples(allocations, annotator_dict, num_classes)
annotations = concat_annotations(annotated)
print(annotations)
# Compute reliability metrics.
effiannos = Annotations(annotations, reannotations=True)
# You can also define a label_generator manually like so,
# if you need more advanced functionality.
# label_mapping = {0.0: 0, 1.0: 1, 2.0: 2}
# label_generator = DefaultLabelGenerator(annotators, label_mapping)
# effiannos = Annotations(annotations, num_classes,
# label_generator=label_generator)
print(effiannos.get_reliability_dict())
# Get agreement info for annotators like so
user_info = effiannos["Larry"]
print(user_info)
agreement = effiannos["Larry", "Moe"]
print(agreement)
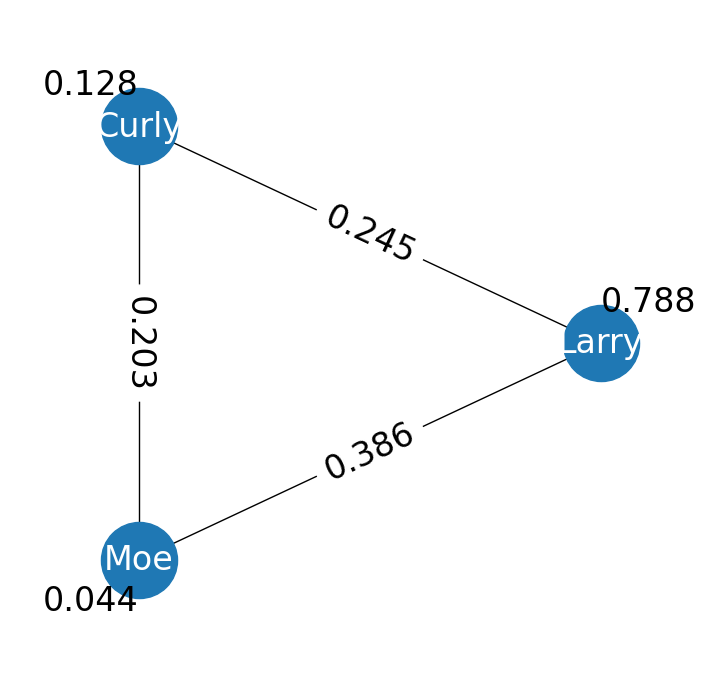
# Edges are inter-annotator reliability
# Nodes are intra-annotator reliability
effiannos.display_annotator_graph()
# The graph isn't very readable with more than 5 or 6 annotators
# In these cases, we can also plot the agreements as a heatmap.
effiannos.display_agreement_heatmap()
The graph should look something like this.